Three Jobs of Containers
Learning from Brian Holt's Intro to Containers
I've been watching Brian Holt's Intro to Containers on Frontend Masters (this is a paid, recorded workshop that is every bit worth the subscription, but also the course notes are available free online) and learned something about containers I thought I should share.
Containers do 3 important jobs for multitenant cloud environments:
- No process should be able to access the filesystem of its neighbor
- No process should be able to see or control the processes its neighbor is running
- No process should be able to deprive system resources (CPU, memory, etc) from its neighbor
If you're a frontendy dev like me, you probably have a vague idea that containers are superior to VMs, and you are maybe aware that serverless functions run inside containers. You've probably even seen an image like this showing how containers are lighter weight than VMs because VMs have OSes in them:

But you've maybe never really thought about how containers are made! Brian starts off his workshop by showing how to make a container from scratch, which at once blows away the magic and also articulates clearly why you would want something like Docker to take care of all the little details for you.
Why Containers
Brian first starts off establishing Why Containers - and implicitly - why containers are the future of deployment and the future of cloud (for many of you, they are already present and boring, but remember the future is unevenly distributed!).
The main thing to understand here, which necessitates the 3 jobs we are about to describe, is that we (and more importantly public cloud vendors) want multiple applications (tenants) to share the same machine, as cost efficiently as possible.
Managing VMs is expensive (in the money sense of the word as well as in the computing speed/efficiency sense) because each VM runs an OS inside a host OS. So we want these apps to run in the same OS, but yet have security and resource-isolation. This isn't just to defend a malicious attacker from snooping its neighbor, but also to be resistant to someone else's badly coded infinite loop to hog or crash the machine and wreck neighbor applications.
Desired Outcomes
So here are three properties we want:
- No process should be able to access the filesystem of its neighbor
- No process should be able to see or control the processes its neighbor is running
- No process should be able to deprive system resources (CPU, memory, etc) from its neighbor
There are more, but these are the big 3 we will discuss.
Job 1: Isolate the Filesystem
No process should be able to access the filesystem of its neighbor
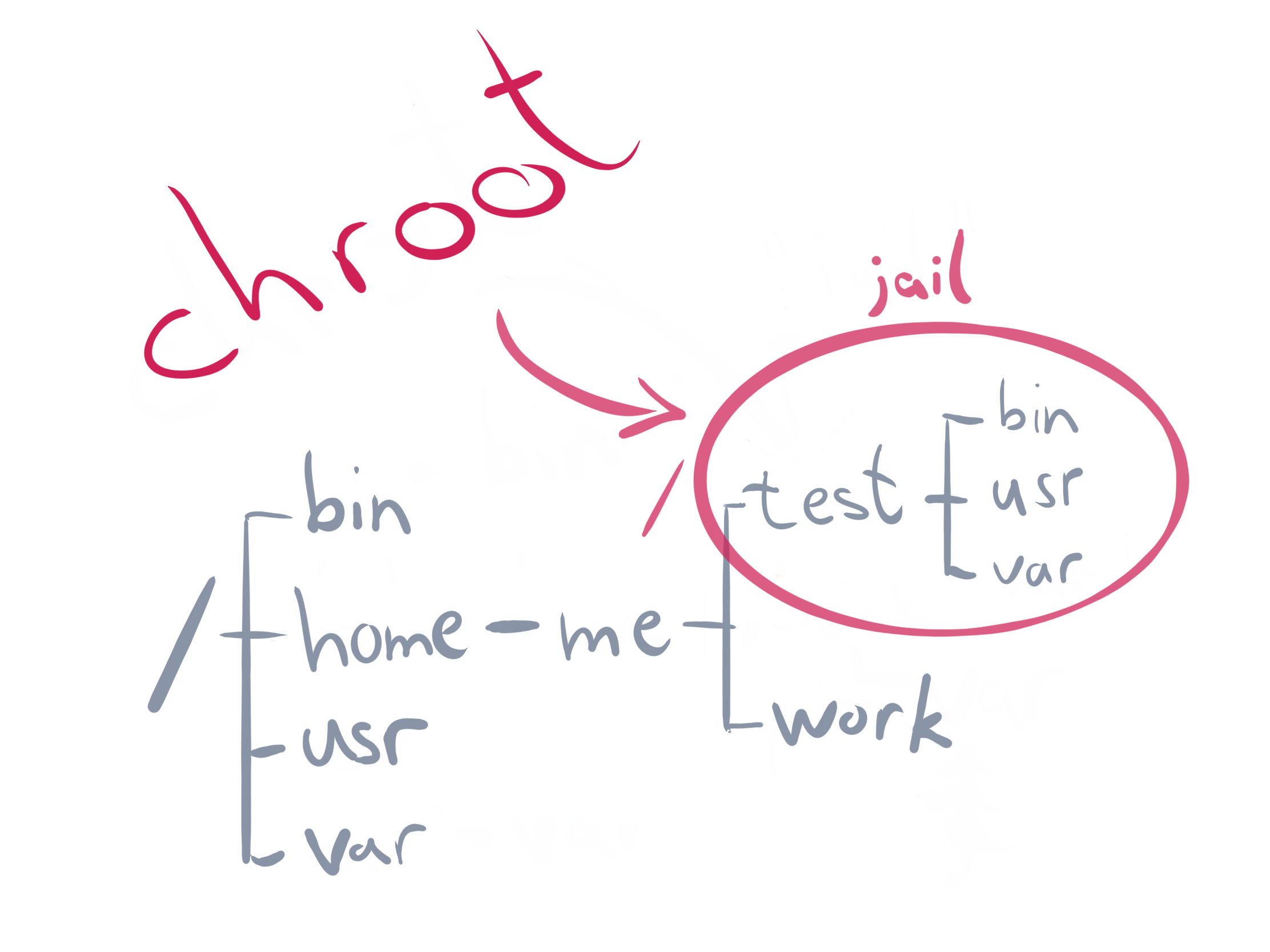
The "hack" here is to use the Linux chroot command. It is a magic command that restricts the root directory of the currently running process, so it can't reach up and out beyond that.
mkdir my-new-root
sudo chroot my-new-root pwd
# chroot: pwd: No such file or directoryAs you can see it isn't as simple as running the command - you have to also copy over all the standard libraries that would normally be on your root path like ls and bash or you can't use them! (see notes for how)
To install these libraries you can use debootstrap, a tool which will install a Debian base system into a subdirectory of another, already installed system:
apt-get update -y
apt-get install debootstrap -y
debootstrap --variant=minbase bionic my-new-root
mkdir my-new-root
sudo chroot my-new-root pwd
/ # now pwd works!Job 2: Isolate Running Processes
No process should be able to see or control the processes its neighbor is running
Processes have a surprising amount of control over other unrelated processes. You can ps to see the other processes running on your system, and arbitrarily kill them:
$ ps
PID TTY TIME CMD
16448 ttys000 0:02.56 zsh -l
57031 ttys000 0:00.19 MY_SUPER_SECRET_RUNTIME
47986 ttys003 1:38.59 /bin/zsh --login
$ kill 57031
# MY_SUPER_SECRET_RUNTIME killedWe obviously can't have that. Enter Namespaces, introduced in 2002 to help with this. You create a namespace with unshare, and give it flags to control what can be locked down for each chrooted environment:
unshare --mount --uts --ipc --net --pid --fork --user --map-root-user chroot /better-root bash # this also chroot's for usThere are 7 kinds of namespaces:
- Mount points (--mount)
- Process IDs (--pid)
- Network (--net): Each namespace will have a private set of IP addresses, its own routing table, socket listing, connection tracking table, firewall, and other network-related resources.
- Interprocess Communication (--ipc): This prevents processes in different IPC namespaces from using, for example, the SHM family of functions to establish a range of shared memory between the two processes.
- UTS (--uts): UTS namespaces allow a single system to appear to have different host and domain names to different processes.
- User ID (--user): build a container with seeming administrative rights without actually giving elevated privileges to user processes
- Control Group: this one seems to be newer.
This is as much to defend from attackers as it is to protect ourselves from ourselves.
Job 3: Isolate System Resources
No process should be able to deprive system resources (CPU, memory, etc) from its neighbor
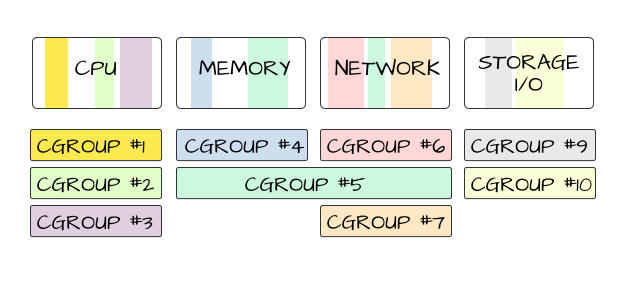
Every isolated environment has access to all physical resources of the server - primarily CPU and memory, but also other things like storage and network access. Google engineers came up with control groups (cgroups) in 2006 to isolate resources to their respective processes.
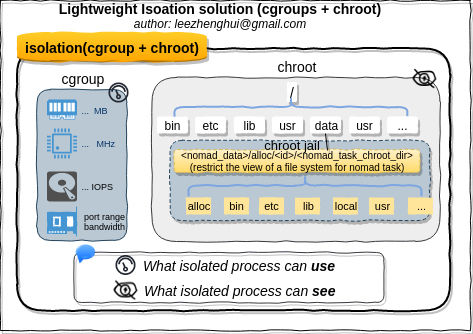
# outside of unshare'd environment get the tools we'll need here
apt-get install -y cgroup-tools htop
# create new cgroups
cgcreate -g cpu,memory,blkio,devices,freezer:/sandbox
# add our unshare'd env to our cgroup
ps aux # grab the bash PID that's right after the unshare one
cgclassify -g cpu,memory,blkio,devices,freezer:sandbox <PID>
# Limit usage at 5% for a multi core system
cgset -r cpu.cfs_period_us=100000 -r cpu.cfs_quota_us=$[ 5000 * $(getconf _NPROCESSORS_ONLN) ] sandbox
# Set a limit of 80M
cgset -r memory.limit_in_bytes=80M sandboxAgain, you can read more in the notes on cgroups.
Conclusion
These are probably not the only jobs of containers, they are just the 3 that Brian highlighted and I thought it was insightful enough to share.
I was going to try to draw some of these systems but didn't think I would do a good job of it so here are some diagrams I found that now make sense:

And of course if you want to learn more like this check out Brian Holt's Intro to Containers on Frontend Masters !
Once you approach technology from First Principles, you learn lasting knowledge that you can reapply in other scenarios, and gain the ability to critical analyze the tradeoffs of the technology for yourself instead of taking other people's thoughts at face value.
Addendum: Firecracker and microVMs
Recent advancements have blurred the line between VM and container. Firecracker from AWS is regarded as a microVM solution:
Until now, you needed to choose between containers with fast startup times and high density, or VMs with strong hardware-virtualization-based security and workload isolation. With Firecracker, you no longer have to choose. Firecracker enables you to deploy workloads in lightweight virtual machines, called microVMs, which provide enhanced security and workload isolation over traditional VMs, while enabling the speed and resource efficiency of containers.
Firecracker comes with a paper writeup, here's a more digestible breakdown:
At the core of Firecracker therefore is a new VMM that uses the Linux Kernel’s KVM infrastructure to provide minimal virtual machines (MicroVMs), that support modern Linux hosts, and Linux and OSv guests. It’s about 50kloc of Rust – i.e. a significantly smaller code footprint, and in a safe language. Wherever possible Firecracker makes use of components already built into Linux (e.g. for block IO, process scheduling and memory management, and the TUN/TAP virtual network interfaces). By targeting container and serverless workloads, Firecracker needs to support only a limited number of emulated devices, many less than QEMU (e.g. , no support for USB, video, and audio devices). virtio is used for network and block devices. Firecracker devices offer built-in rate limiters sufficient for AWS’ needs, although still considerably less flexible than Linux cgroups.
Further reading
- Bryan Cantrill on a more detailed history of Containers
- https://www.docker.com/blog/intro-guide-to-dockerfile-best-practices/
- https://earthly.dev/blog/chroot/