Unsupervised Learning: Feature Selection
This is the 15th in a series of class notes as I go through the Georgia Tech/Udacity Machine Learning course. The class textbook is Machine Learning by Tom Mitchell.
The Goal of Feature Selection
There are often too many features which might be important in our data. Since even in the binary case these cause 2^N permutations, it is good to try to reduce N. Imagine out of 1000 possibly important features you were able to narrow it down to 10 that really matter. Intuitively, this is the same as interpreting the features (knowledge discovery).
Feature Selection (aka optimization over arbitrary number of parameters) is known to be NP-hard. Solving it takes exponential time.
There are two general approaches to tackling this.
Filtering and Wrapping
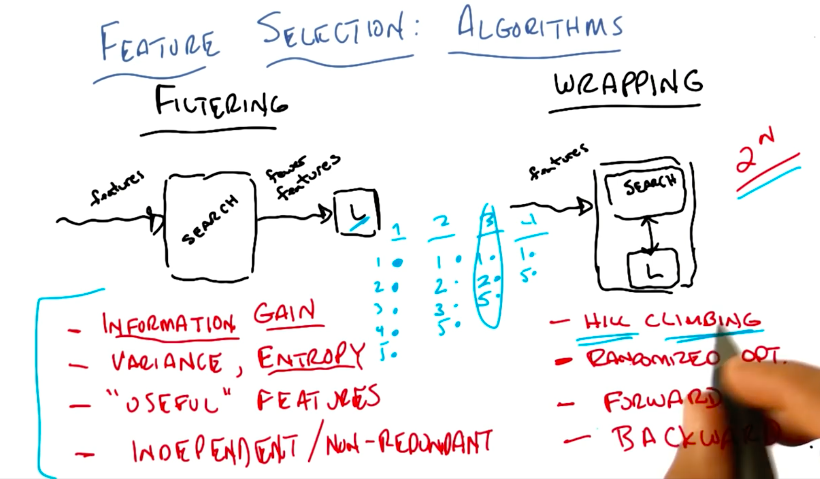
Approach 1: Filtering
Reducing many features to a set of fewer features through a maximizing (aka "search") algorithm of some sort, that you then pass to your learning algorithms. The scoring is buried in the search algorithm, without reference to the learner.
The process flows forward, which is simple to set up, but the problem is that there isn't any feedback.
Although you can't run the learner ahead of time in filtering, you can still evaluate the features, for example for information gain. You could in fact have your search algorithm just be a decision tree, and pass the nodes used in the DTree to your learner as your reduced features. So that is like using the inductive bias of DTrees to choose features, then passing it on to your other learner (eg NN or kNN) with some other bias. This is particularly helpful when this other learner (like NN or kNN) suffers from the curse of dimensionality.
You can also use other things as filtering criteria:
- Information Gain
- proxies of Information Gain, e.g. Variance, Entropy, running a neural net and pruning away low weight features so "useful" features remain
- Indepdenent/Non Redundant Features
Approach 2: Wrapping
Run your learning algorithm over a subset of features, the learning algorithm reports a score, and that is the driver for your maximizing (aka "search") algorithm. The search for features is wrapped around whatever your learning algorithm is. Feedback is inbuilt.
You can use a few methods to do Wrapping search without paying exponential (2^N) cost:
- any randomized optimization method (e.g. Hill Climbing)
- forward sequential selection
- backward elimination
Forward search involves running sequentially through each feature, and seeing which adds to the best you currently have. Repeat (running again through each remaining feature) until your score no longer improves by enough. This is a sort of hill climbing.
Backward search involves starting with ALL N features and looking for which you can eliminate. Whichever set of N-1 features work out best go on to the next round and you drop the unlucky feature. Repeat until the score drops too much.
Comparison
Filtering is faster than wrapping because you can apply any algorithm that only looks at the features and applies filtering (no learning involved). Although it is an exponential problem, you can choose your filtering to be as fast as you want it to be.
Wrapping takes into account model and bias, but is muuuuch slooooower because the learning has to be done.
Filtering only cares about labels, while Wrapping takes advantage of the learner, but with an exponential search problem.
Relevance vs Usefulness
There are formal terms we want to define here.
Relevance measures the effect on the Bayes Optimal Classifier (BOC):
Xiis strongly relevant if removing it degrades BOCXiis weakly relevant if- not strongly relevant
- there is a subset of features S such that adding Xi to S improves BOC
- else it is irrelevant
Relevant is about information.
Usefulness measures effect on particular predictor, more precisely, the effect on error given a particular classifier.
Feature selection is often an exercise in selecting the most relevant features, but often what we actually want is usefulness.
Wrapping is slow but useful, Filtering tries to optimize for relevance but ignores the bias in our learner that we actually want.
Next in our series
Hopefully that was a good introduction to Feature Selection. I am planning more primers and would love your feedback and questions on:
- Overview
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
- Markov Decision Processes - week of Mar 25
- "True" RL - week of Apr 1
- Game Theory - week of Apr 15