Reinforcement Learning: Game Theory
This is the 19th and last in a series of class notes as I go through the Georgia Tech/Udacity Machine Learning course. The class textbook is Machine Learning by Tom Mitchell.
Why Game Theory in Reinforcement Learning
What we know about RL so far has been entirely based on single actors in an environment. However, optimal strategies change significantly when the behavior of other actors is taken into account, which may change the expected payoffs of our own actions. This is why we incorporate Game Theory in RL.
Minimax
We define a simple game between two players with a range of choices, with zero sum payoffs (one player's win is another's loss), deterministic results, and perfect information.
B
L M R
L 1 -3 0
A
R 0 3 -1Even in this situation it is not clear which choice B or A should take. One heuristic to adopt is for A (which wants the lowest number, for example) to always look for the maximum number, and minimize that. And vice versa for B. Each considers the worst case response from the other. So A picks L. This is called minimax.
However if B also only pays attention to itself and does minimax (it wants higher values), it will pick M, which ironically hands A the -3 it wants. So B must consider what A is likely to do in formulating it's own actions. In this case it is best to pick L where the worst case scenario isn't so bad.
Von Neumann's theory
In a 2 player, zero sum deterministic game of perfect information,
minimax===maximinand there always exists an optimal pure strategy for each player.
This is to say, there is always a definite value of the game if we assume the players follow minimax or maximin, and they are the same.
More reading: https://cs.stanford.edu/people/eroberts/courses/soco/projects/1998-99/game-theory/neumann.html
as well as the Theory of Games and Economic Behavior
and Andrew Moore on Zero-Sum Games
Relaxing assumptions
If we relax the requirement of determinism, we get the same result under Von Neumann - just that all choices are made based on expected value.
If we relax the requirement of perfect information, a lot of complexity comes into the picture. Von Neumann is broken.
The reliance on a pure strategy is important for Von Neumann. And if each player is too consistent, they become predictable, and thus exploitable. Thus a mixed strategy varies strategies based on a probability distribution. However if for every p selected by A, a corresponding mixed strategy governed by p' can be chosen by B to offset it, there is still a probabilistic equilibrium where the payoffs meet:
Lastly, if we relax the assumption of a zero-sum game, we can get situations like the Prisoner's Dilemma where cooperation can result in better average outcomes than each can independently get, if they don't betray the other. However because the betrayal strategy dominates in each scenario independently,
See Andrew Moore's slides on Non Zero Sum Games
Nash Equilibrium
Given n players with strategies, you know you are in Nash Equilibrium if you take any player and changed their strategy, and they would be worse off. No one person has any reason to change their strategy. There are a few other minor results that come out of this definition.
Repeated games
Most games discussed up til this point are finite, one-off games. What if we could play several rounds of the game, taking into account information from prior rounds? This causes a form of communication of strategy to take place as well as establishes consequences of taking selfish strategies where a positive sum result could have been possible. As such, it causes strategies to lean towards cooperating.
This can be modeled as "trust", but only makes sense if the total number of games is unknown. (By induction, if you know you are at the last round of a repeated game, then it is a one-off game, so the second last round needs to take that into consideration, and so on all the way to the first round. So n repeated games with a finite, known n simply lead to n repeated Nash Equilibria.).
So assuming an unknown number of games (with a probability of ending gamma, which looks remarkably similar to a discount factor), a great strategy to encourage collaboration is the Tit for Tat strategy. This establishes communication and consequences between rounds, socializing the result of the net suboptimal outcome. It turns out that TfT is best suited for gamma values above a certain level dependent on the payoffs, because if not then the benefit of being selfish outweighs the odds of consequences.
The Folk Theorem of Repeated Games
Tit for Tat is an example of the general idea that the possibility of retaliation opens the door for cooperation. In game theory, the term "folk theorem" refers to a specific set of payoffs that can result from Nash strategies in repeated games.
The Minmax profile is a pair of payoffs, one for each player, that represent the payoffs that can be achieved by a player defending itself from a malicious adversary. (More description)
The feasible payoff profile is any mix of available strategies:
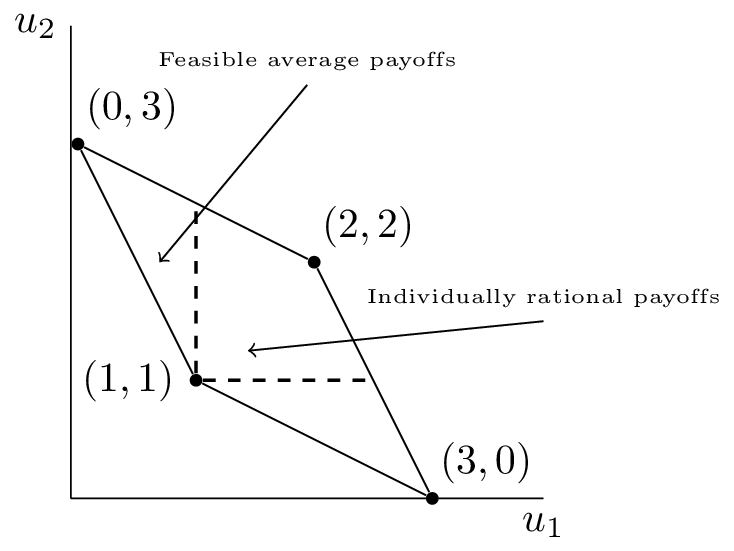
Some range of feasible payoffs is going to be better than whatever can be individually achieved (incentive for cooperation), leading to the Folk Theorem:
Any feasible payoff profile that strictly dominates the minmax/security level profile can be realized as a Nash equilibrium payoff profile, with sufficiently large discount factor.
In other words, if you refuse to cooperate, I can push you down to the minmax profile, instead of letting you get benefits better than you can get on your own.
Subgame Perfect
The threat cannot be too extreme as to be implausible - to the extent of harming your own interests just to punish my actions. The formal term for a plausible threat is subgame perfect - where you are giving the best response independent of history.
Implausible threats like the Grim trigger are not subgame perfect because you can always drop the strategy to improve your own interests.
The combination of TfT vs TfT is not subgame perfect, because instead of instant retaliation you can pick forgiveness.
There is a variant based on agreement/disagreement called the Pavlov strategy that offers more memory, that -is- subgame perfect, because disagreements lead to defections which lead to agreements which lead to cooperation. Wonderful! Now it becomes a plausible threat that is better to enforce than TfT. (More on this)
Stochastic Games (or Markov Games)
This is a generalization of MDPs and Repeated Games that is a formal model for Multiagent Reinforcement Learning.
Next in our series
Further notes on this topic:
- class notes
- Paper on Computational Folk theorem which shows you can construct subgame perfect Nash eq. for any game in polynomial time.
- Coco values - adding side payments to encourage nash equilibria (paper)
Hopefully that was a good introduction to Game Theory. Feedback and questions are welcome. The entire series is viewable here:
- Overview
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
- Markov Decision Processes - week of Mar 25
- "True" RL - week of Apr 1
- Game Theory