Networking Essentials: Traffic Engineering
This is the tenth in a series of class notes as I go through the free Udacity Computer Networking Basics course.
This is the second of a 3 part miniseries on Network Operations and Management.
What is Traffic Engineering?
Traffic Engineering is how network operators deal with large amounts of data flowing through their networks. They reconfigure the network in response to changing traffic loads to achieve some operational goals, like:
- Traffic ratios in a peering relationship (aka "peering ratios")
- Relieve congestion
- Balance load more evenly
Software Defined Networking is used to make Traffic engineering easier in both data center networks and transit networks.
Doesn't the Network manage itself?
Although we have covered how TCP and Routing both manage themselves (adapting to congestion, or to topology changes), network still may not run efficiently. There may be needless congestion with unused idle paths. So the key question a traffic engineer address is: "How should Routing adapt to Traffic?"
Intra-domain Traffic Engineering
In a standard network topology, every link has a weight associated with it. A very simple configuration is to tweak the weight according to your priorities. For example:
- Link weight inversely proportional to capacity
- Link weight proportional to propagation delay
- Some other Network-wide optimization based on traffic
The 3 steps of Traffic Engineering
- Measure: figure out the current traffic loads
- Model: how configuration affects the paths in the network
- Control: reconfiguring the network to assert control over how traffic flows
As an example, you can measure topology and traffic, feed them into a predictive "What-If" model, optimizing for an objective function, generating the changes you want to make and then feed that back into the network by readjusting link weights.
The objective function is an important decision in this process. We can choose to minimize the maximum congested link in the network, or just evenly splitting traffic loads across links, or something else.
Optimizing for the Link Utilization Objective
Even a simple model of the "cost of congestion" as increasingly quadratically (as a square) with congestion is an NP-complete problem - so it is not mathematically solvable. Instead we have to search through a large set of combinations of link weight settings to find a good setting. In practice, this is fine.
We also have other constraints to our search, which reduce the number of things we try. For example we want to minimize changes to the network. Often just 1 or 2 link weight changes is enough. Our solution must also be resistant to failure and robust to measurement noise.
Interdomain Traffic Engineering
Recall that Interdomain routing concerns routing that occurs between domains or ASes. (See our discussion of the Border Gateway Protocol). Interdomain Traffic Engineering thus involves reconfiguring the BGP policies or configurations that are running on individual edge routers in the network.
Note:
- Changing these policies on the edge can cause routers inside the network to direct traffic to or away from certain edge links.
- We can also change the set of egress links for a particular destination, based on congestion, or change in quality of link, or some violation of a peering agreement (like exceeding an agreed load over a certain time window)
Our actions derive from our goals for Interdomain TE:
- Predictability (predict how traffic flows will change in response to changes in the network configuration)
- Downstream neighbors may make changes in response to our changes, and this is a problem for us again
- So we should not make any globally visible changes
- Limit influence of Neighboring domains
- So we should make consistent route advertisements and limit the influence of AS path length
- Reduce overload of routing changes (i.e change as few IP Prefixes as possible)
- So we group prefixes according to those that have common AS paths and move traffic by grouped prefixes
Multipath Routing
One technique applicable in Inter- and Intra-domain routing is Multipath routing - routing traffic across multiple paths. The simplest example of this is setting an equal weight on multiple paths, or Equal Cost Multi Path (ECMP). This would send traffic down those paths in equal amount.
A source router can also set percentage weights on paths, for example 35% on one and 65% on another, and it might do this based on observed congestion!
Data Center Networking
Data Center Networks have three characteristics:
- Multi-tenancy - allows cost sharing, but also must provide security and resource isolation
- Elastic resources - allocating up and down based on demand. Allowing pay per use business model.
- Flexible service management - ability to move workloads to other locations inside the datacenter with virtual machine migration.
So our requirements develop accordingly. We need to:
- load balance traffic
- support VM migration
- saving power
- Provisioning (when demand fluctuates)
- providing security guarantees
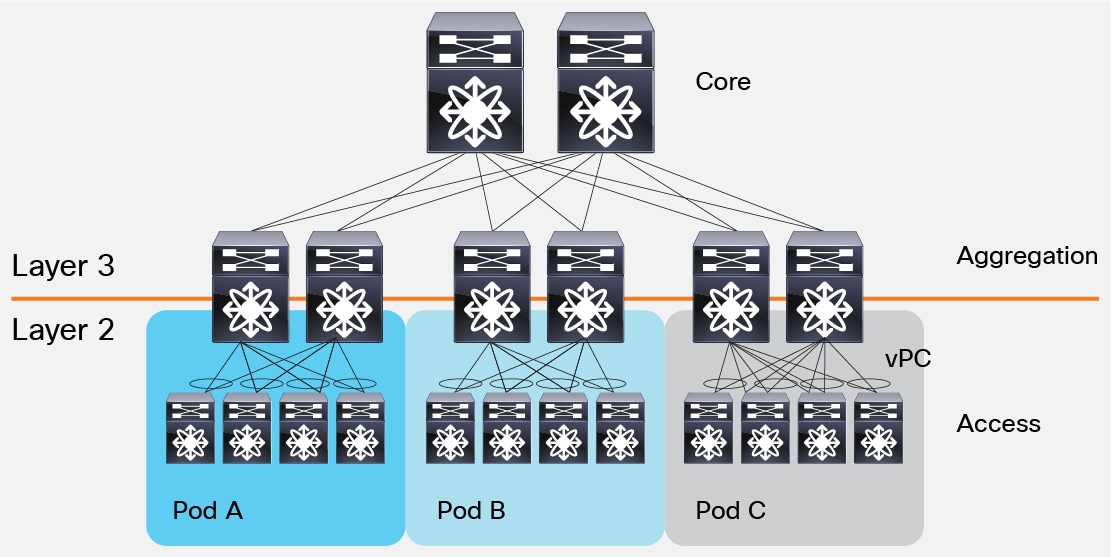
A typical Data center topology has 3 layers:
- The Access layer connects to the servers themselves
- The Aggregation layer
- The Core layer
The Core layer is now commonly done with a layer 2 topology which makes it easier to migrate and load balance traffic, but is harder to scale because we now have x0,000s of servers on a single, flat topology.
This hierarchy can also create single points of failure and links in the Core can become oversubscribed. In real life datacenters the links at the top can carry up to 200x the traffic of links at the bottom, so there is a capacity mismatch.
Scaling in the Access Layer
One interesting way to deal with the Scaling issue is "Pods".
In the Access layer, every machine has an independent MAC address. This means every switch in the layer above needs to store a forwarding table entry for every single MAC address. The solution is to assign groups of servers by switch as "Pods", and assign them "pseudo-MAC addresses". Thus servers only need to maintain entries for reaching other Pods in the topology.
Load Balancing across the Data Center
To spread traffic evenly across the servers in a Data Center, Microsoft invented Valiant Load Balancing in 2009. It achieves balance by inserting an "indirection level" into the switching hierarchy. The switch is selected at random - and once it is selected it finishes the job of sending the traffic to its destination. Picking random interaction points to balance traffic across a topology actually comes from multiprocessor architectures and has been rediscovered for data centers.
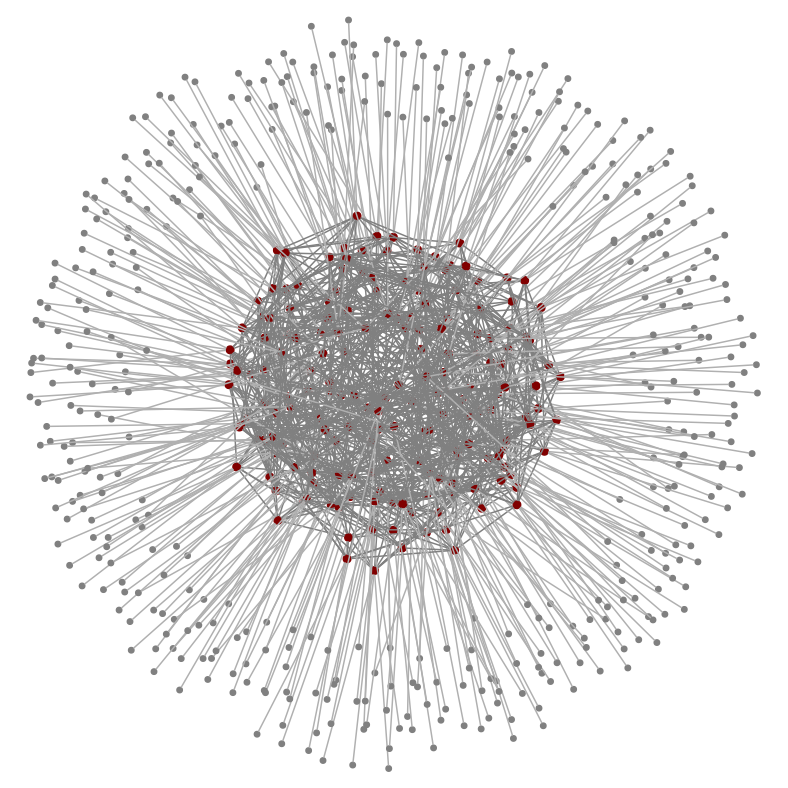
Jellyfish Technique
Read the Jellyfish paper here
Similarly to Valiant, Jellyfish networks Data Centers randomly, to support high throughput (eg for big data or agile placement of VMs) and incremental expandability (so you can easily add or replace servers and switches).
The structures of Data Centers tend to constrain expansion. For example, the Hypercube requires 2^k switches (k = number of servers). FAT trees are more efficient (O(k^2)) but still quadratic.
Here is a FAT tree - you can see the congestion at the top (Access) level:

Jellyfish's topology is a "Random Regular Graph" - each graph is uniformly selected at random from the set of all "regular" graphs. A "regular" graph is one where each node (a switch, in this context) has the same degree.
Here is a Jellyfish - having no structure is great for robustness!
Next in our series
Hopefully this has been a good high level overview of how Traffic Engineering works. I am planning more primers and would love your feedback and questions on: