Networking Essentials: Switching
This is the second in a series of class notes as I go through the free Udacity Computer Networking Basics course.
Let's build our own Intranet from scratch. What are the first problems we will run into?
Say we have just two machines, each connected by some network interface (like an Ethernet Adapter).

Manufacturers assign each machine (or host) a physical address (also known as a MAC address) so we can tell them apart. We also assign each machine a unique IP address - this is public information but the MAC addresses are not.
As we previously discussed with packet switching, individual packets of data that we send from one host to the other, also called datagrams, simply have their destination addresses stamped on them. (More accurately speaking, the host encapsulates the datagram in an Ethernet frame which has the destination MAC address on it on it.)
Seems simple enough, but we've already run into our first problem.
Remember we're setting up our Intranet from scratch. The machines are brand new, and have just been hooked up for the first time. How does a host learn the MAC address of another host??
Address Resolution Protocol
The ARP is pretty much the only way possible to solve this problem given the constraints:
- For a first time transmission to a new IP address, a host asks everyone in its network for someone who has that specific IP address
- The one who matches that IP address responds (in a DM 😎) with it's MAC address
- The host starts building a simple table mapping each IP address to a MAC address based on received responses through its lifetime
- For future transmissions to that IP address, the host doesn't have to ask anymore, it can just start dispatching datagrams to the stored MAC address right away to anyone in its network
Pretty neat! You may ask: why so complicated? Why must we have two sets of addresses per machine? There are many practical considerations today but at the most fundamental this is a result of the multilayered network model we discussed in the previous post - you are translating from the Link Layer (MAC address) to the Internet Layer (IP address) and they are decoupled for better or worse.
Likewise, the packets of data we send are datagrams at the low level, but what gets sent over the Internet Layer is actually Ethernet frames (with the destination addresses attached).
Hubs: Broadcasting
Ok so we have figured out how to send data between two machines. How do you scale this up to, say, 10 machines?
First let's consider an idea called a Hub. Hubs are the simplest form of interconnection which help you broadcast messages. If one host sends a frame to a Hub, the Hub will broadcast that frame to all other Hubs and hosts it is connected to.
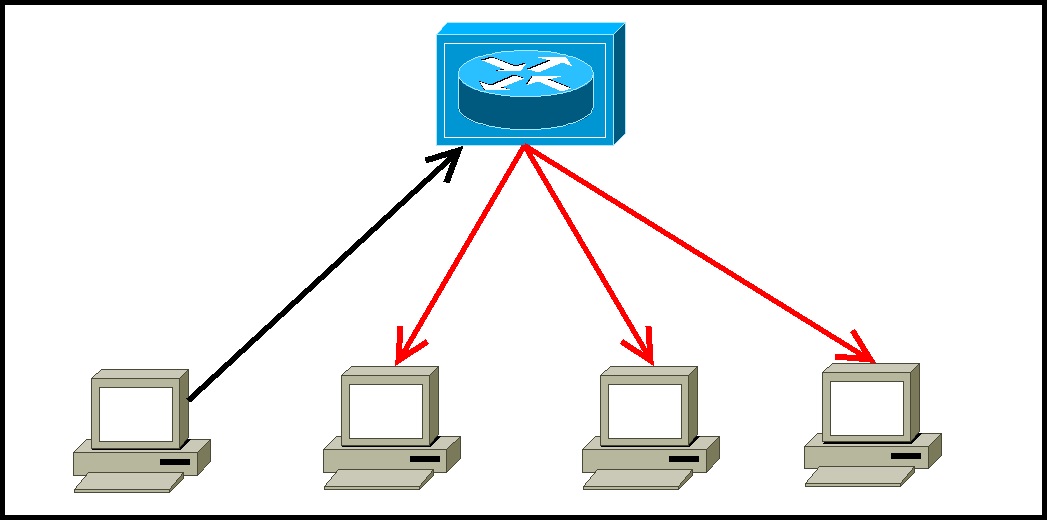
This is known as flooding and it causes latency and can lead to collisions in any given port.
If a hacker wanted to overwhelm the network, all they would have to do is send a bunch of frames to a couple of hubs and the hubs would happily bring down the network on the hacker's behalf. That (and a bunch more good reasons) is why we don't want Hubs to broadcast -everything- and we should try to isolate traffic from hubs.
Switches: Traffic Isolation
Switches subdivide our network into segments. A frame from within a segment that is bound for a destination in the same segment as the origin never gets broadcasted to other segments. Switches can work with Hubs:
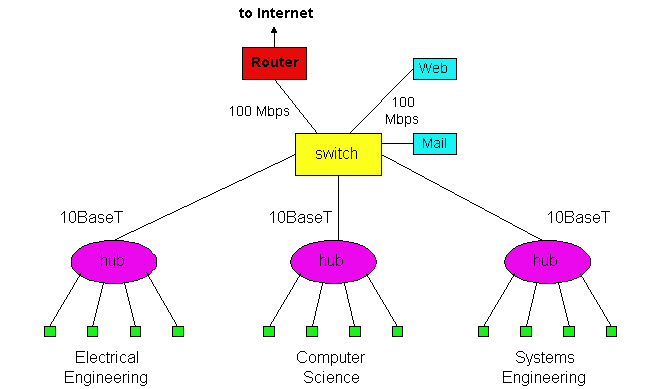
So within a segment, a hub is responsible for broadcast, but the switch's job is to ensure that the only data that leaves a segment is data meant for other segments. Switches are smarter than just broadcasting that data as well, so they also build up switch tables mapping destination MAC addresses to the switch's output ports. This is called a Learning Switch, and when it encounters a new address it doesn't know it floods all its ports and records the address of whoever responds.
However the flooding can go out of control when there are loops introduced in the network (multiple connections to a node added for resilience in case any particular connection fails) and the switch floods data it has already flooded before (creating a cycle).
Spanning Trees: Breaking cycles
We break cycles in Ethernet networks with the Spanning Tree Protocol. The basic idea is to have a subset of the network that touches all the nodes of the network, but doesn't have any cycles. We would then make our switches only flood/broadcast only the connections which are on the spanning tree, thus guaranteeing that the switches won't flood themselves.
Building a Spanning Tree is a messy recursive algorithm:
- the Switches pick a root for a tree (eg switch with smallest ID, but the actual election process is wonderfully complicated - If all switches have the same switch ID, then the switch with lowest MAC address (number will out rule letters) will become the root switch, or you can force a particular switch to be the root switch by creating loopback addresses.)
- switches pass on their distance to root to other switches they are connected to
- each switch excludes any link not on the shortest path to root (so every switch only has one outgoing link, but could have multiple inbound links from switches further away from the root)
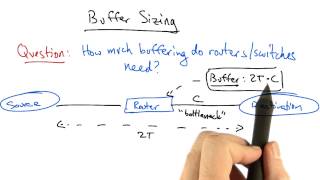
Buffer Sizing
Because we've chosen to use statistical multiplexing, our Switches also need a buffer to store the multiple packets that may be coming in at the same time. How much do they need?
Given a round trip delay of 2T and the link's bottleneck capacity is C, the rule of thumb for the buffer size is 2T * C. This just represents the maximum amount of outstanding data that could be enroute between source, router, and destination at any point in time. You can derive this mathematically or just visualize it as the height of the sawtooth flow but that is beyond scope for us here.
Aside: The 2T * C max buffer size rule of thumb is unnecessary for real life networks. Backbone switches can have more than 20,000 connections at once, and the TCP flows that come in on them aren't going to be synchronized. This means the min and max of the sawtooth are very likely not a linear multiple of all the connections and the buffer needs will likely converge to a statistical average. So more derivation leads us to conclude that a good buffer assuming TCP flows are non-synchronized is 2T * C / sqrt(N).

note the lower sawtooth height in the descynchronized scenario
Switches vs Routers
Switching and Routing are somewhat competing, somewhat parallel concepts. In this post we have explored Switching as a simpler concept for efficiently funneling data through a decentralized network. But next we will explain Routing in contrast to Switching.
Switches are on Layer 2 of the OSI model, the Ethernet layer. They are auto-configuring (as we have seen above, they just figure out their own spanning trees and address resolution), and forwarding tends to be fast. However spanning tree and ARP queries pose a significant load on the network.
Routers and VLANs are on Layer 3 of the OSI model, the IP layer. They are not restricted to spanning trees - multipath routing uses multiple paths for increased bandwidth/resilience, and advancements like Software Defined Networking further blur the lines between Layers 2 and 3. Their primary purpose is to break up broadcast domains. We will explore this in our next post.
Next in our series
Hopefully this has been a good high level overview of why we need Switches and how they might work if we were to make our own Internet. I am planning more primers and would love your feedback and questions on: