Networking Essentials: Architecture and Principles
This is the first in a series of class notes as I go through the free Udacity Computer Networking Basics course.
The Fundamental Goal
For much of this information our chief reference is David Clark's The Design Philosophy of the DARPA Internet Protocols paper published in 1988.
The fundamental design goal of the Internet was to achieve "effective multiplexed utilization of existing interconnected networks". In English, that means we share usage of connected networks.
The goal of sharing is solved by statistical multiplexing (aka packet switching). In packet switching, every packet sent carries it's own destination information, so it can be forwarded along, similar to how a letter sent through the mail has its destination on it. This means the network can deliver the packet on a best effort basis, which enables sharing because many senders can use the same network at the same time but at the risk of some droppped packages. This is in contrast to circuit switching, which is more like a phone network - direct connections are established, transmissions have less chance of losing/dropping packets, but if the available capacity is taken up, you're out of luck.
The goal of connecting networks is solved by the "narrow waist". With reference to the OSI 7 layer systems model, our network layer is very thin - it mostly consists of the Internet Protocol! IP provides guarantees to the transport layer sitting above it, usually TCP or UDP, and the combination of TCP/IP is the most common end to end data transmission stack. On top of this solid foundation we can layer whatever protocols we want to send data, e.g. HTTP for websites or SMTP for mail! Below the IP layer we also have the link layer and physical layers with still more protocols like Ethernet and SONET. But the point is, the middle network layer is "narrow" - it just consists of IP. This means it is fairly easy to get any device on the network, it just has to speak IP!
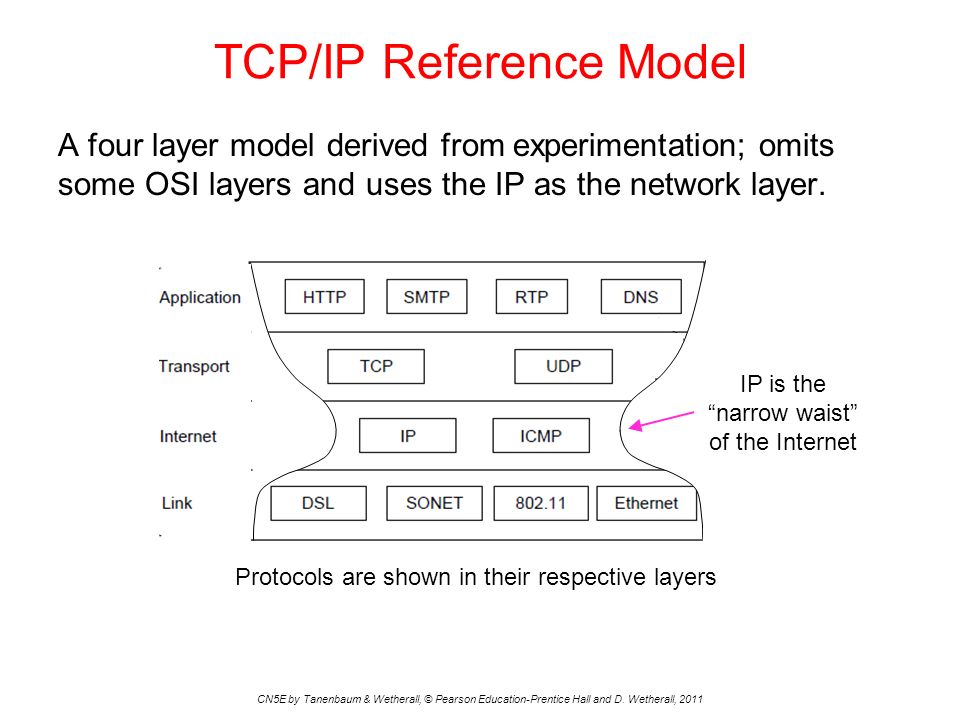
Secondary Goals
The secondary goals all consist of further defining what the word "effective" really means in the "fundamental goal" listed above:
- Survivability: Internet communication must continue despite loss of networks or gateways.
- Heterogeneity 1: The Internet must support multiple types of communications service.
- Heterogeneity 2: The Internet architecture must accommodate a variety of networks.
- Decentralization: The Internet architecture must permit distributed management of its resources.
- Cost: The Internet architecture must be cost effective.
- Ease: The Internet architecture must permit host attachment with a low level of effort.
- Trackability: The resources used in the internet architecture must be accountable.
We don't have space to discuss the implications of them all here, but will dwell on a few important ones.
Survivability
We take this to mean that the network should continue to work even if some devices fail or are compromised.
How do we achieve this? One way to do it is through replication, where we duplicate state in another node so that there is always a backup ready to take over in case of failure. However this trades off against cost, another of our goals.
Another interesting method is fate-sharing - where if the node disconnects, we consider it acceptable to simply lose all information relevant to that node.
Heterogeneity
The Internet's "narrow waist" design allows multiple protocols to be supported over IP, not just TCP (as previously discussed). This lends itself very well to picking the right protocol for the job, for example picking UDP for the purpose of streaming data since it is more important to be realtime than to be completely lossless. You can even use a combination of protocols to get the best of both speed and losslessness.
The "best-effort" principle of delivery also means data can be delivered over and between any sort of network (including carrier pigeon!!) with the tradeoff of difficulty of debugging since no failure data comes back.
Decentralization
Distributed management of resources can be seen in how Addressing is achieved - which I will detail in a future primer. We have five Regional Internet Registries worldwide - In the US we have ARIN and the European equivalent is RIPE.
We also have decentralization in naming - DNS delegates the responsibility of assigning domain names and mapping those names to Internet resources by designating authoritative name servers for each domain. Routing through Border Gateway Protocol (BGP) is decentralized as well between peers and communities. We will also return to both in a future primer.
Because no single entity is in charge, the Internet has been able to grow organically and is very stable. However the lack of ownership also makes it hard to address problems.
Problems and Growing Pains
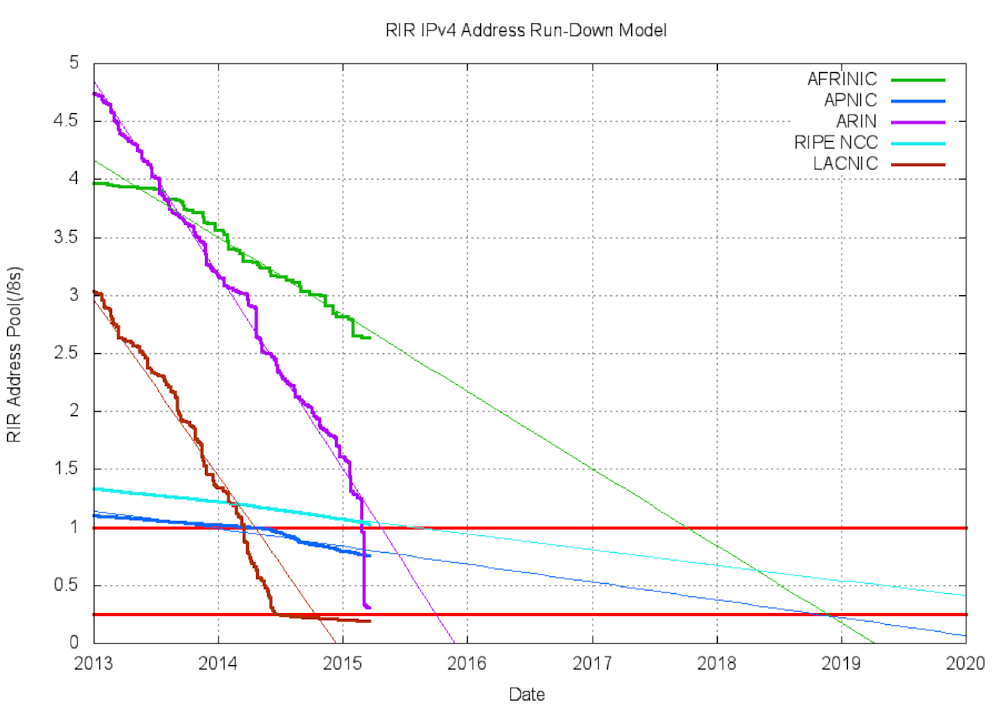
Many of the problems we see on the Internet today are a direct result of the needs of the network outgrowing the design considerations of the 70's and 80's:
- We are running out of IPv4 addresses - only 4 billion IP addresses, inefficiently allocated.
- Congestion Control - our networks get very unperformant over flaky connections, especially because retransmissions are triggered. I will cover this in a future primer.
- Routing - a topic I will cover in a later primer, but basically it has no security, is easily misconfigured, and exhibits poor convergence and non-determinism. But it sorta works.
- Security deserves its own primer as well: methods for encryption and authentication exist, but we haven't done so well at making sure that they are used. Also key management and secure software deployment are open problems.
- Denial of Service - the Internet maybe does too good of a job delivering packages to the recipient, even if the recipient doesn't wan't them.
Next in our series
Hopefully this has been a good high level overview of why we need Switches and how they might work if we were to make our own Internet. I am planning more primers and would love your feedback and questions on: